

Tuần 3 trong course Machine Learning của giáo sư Andrew Ng trên Coursera.
Xem các bài viết khác tại Machine Learning Course Structure
1. Classification and Representation
1.1. Sigmoid Function or Logistic Function
Trong bài toán phân loại (classification), mặc dù ta có thể tiếp cận nó bằng các thuật toán linear regression đã biết bằng cách tạm thời quên đi giá trị của y chỉ có thể là 0 hoặc 1.Cách tiếp cận này có vẻ không được tốt cho lắm. Giá trị của 
Để giải quyết vấn đề này, ta sẽ biến đổi hàm hypotheses 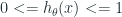


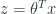

biểu thức trên có biểu diễn đồ thị như sau:

Function g(z) có thể biểu diễn bất kỳ số thực nào nằm trong khoảng từ 0 đến 1.

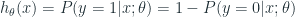

1.2. Decision Boundary
Dựa vào Logistic function ở trên, ta có thể `biến đổi` hàm hypothesis của ta lại thành như sau:
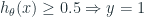

Function g(z) hoạt động như sau:
when

Nhớ rằng:


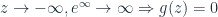
Như vậy, ta có thể viết:
when
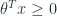
Từ những phát biểu trên, ta có thể viết


Decision Boundary chính là đường phân chia vùng y = 0 và vùng y = 1, được tạo ra bởi hàm hypothesis của chúng ta
2. Ví dụ
Ta có ví dụ sau:
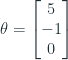


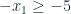

vậy đồ thị của chúng ta sẽ giống như sau

Lưu ý rằng tùy vào hàm hypothesis và các tham số theta, hình dáng boudary line có thể thay đổi tương ứng
