
Tuần 2 trong course Machine Learning của giáo sư Andrew Ng trên Coursera. Trong phần này, bạn sẽ thấy linear regression được mở rộng thành multiple input features, và những best practices để thực hiện linear regression.
Xem các bài viết khác tại Machine Learning Course Structure
- 1. Mutiple Features
- 2. Gradient Descent cho Multiple Variables
- 3. Gradient Descent in Practice
- 4. Features và Polynomial Regression
1. Mutiple Features
Linear Regression với multiple features còn được biết đến với cái tên multivariate linear regression.
1.1. Ký hiệu
= giá trị của feature
jtrong training example thứi.= input (feature) thứ
icủa training example.- m = số training example
- n = số features
1.2. Hypothesis
Như vậy, hàm hypothesis của chúng ta được viết lại như sau:
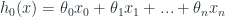
với 
1.3. Trick
Áp dụng các kiến thức về phép nhân matrix đã học ở bài trước, ta có như sau

Trên đây là công thức của hàm hypothesis được rút gọn thành phép nhân matrix với vector.
2. Gradient Descent cho Multiple Variables
Công thức cho thuật toán Gradient Descent thì y hệt như cũ. Ta chỉ lặp lại nó cho n features mà thôi.
Lặp lại cho tới khi hội tụ:
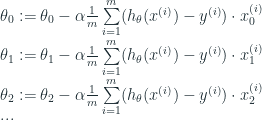
hoặc diễn giải theo một cách khác:
với j:= 0...n
Đối với
,

3. Gradient Descent in Practice
3.1. Feature Scaling và Mean Normalization
Khi các features có giá trị giao động trong các khoảng cách xa nhau, thì thuật toán Gradient Descent thường tốn nhiều thơi gian để tìm ra kết quả.
Ví dụ ta có 2 feature là diện tích nhà và số phòng ngủ:
200 < Diện tích nhà < 2000 1 < Số phòng ngủ < 5
Nếu vẽ đồ thị cho hàm hypothesis dự đoán giá nhà, bạn sẽ thấy nó là một dạng đồ thị hình cái tô với đáy rất nhọn, nhưng dẹp. Điều này làm cho mỗi step của gradient descent trải dài về bề ngang, nhưng không đi nhanh về điểm hội tụ, làm tổng thời gian chạy thuật toán gradient descent tăng lên.

hình ảnh chỉ mang tính chất minh họa 😉
Ta có thể tăng tốc gradient descent bằng cách biến đổi các giá trị của feature cho nó nằm trong một khoảng gần giống nhau. Lý do là 
Nhìn chung, ta sẽ biến đổi sao cho:

hoặc

Trên đây chỉ là ví dụ, mục tiêu là làm cho vùng giá trị của các feature càng gần nhau càng tốt.
2 kỹ thuật để làm chuyện này là Feature Scaling và Mean Normalization.
Feature Scaling là chia input với khoảng giá trị (max – min).
Mean Normalization là input – giá trị trung bình của input.
với:
: trung bình của feature i
: Max – min hoặc độ lệch chuẩn
Max – min sẽ cho ra kết quả rất khác với độ lệch chuẩn.
3.2. Learning Rate
Để xác định tham số 
- Vẽ đồ thị với trục x = số bước lặp của gradient descent, trục y = giá trị của
. Nếu
- Automatic convergence test: Xác định điểm hội tụ khi giá trị
Người ta đã chứng minh được rằng, nếu learning rate
Túm lại:
* Nếu
* Nếu
4. Features và Polynomial Regression
Ta có thể cải thiện features và dạng của hàm hypothesis bằng nhiều cách.
Một trong số những cách đó là kết hợp các feature lại với nhau. Ví dụ như khi ta có 2 feature là dài và rộng, ta có thể kết hợp chúng thành diện tích = dài * rộng.
Ngoài ra, không phải lúc nào ta cũng có thể sử dụng được hàm hypothesis là một đường thẳng, nhất là khi nó không “vừa” với bộ data. Lúc này, có thể biến đổi nó một chút, hoặc bẻ cong nó bằng cách nâng lũy thừa, hoặc lấy căn của các features (hoặc bất cứ dạng nào khác đều được).
Ví dụ:

Ta có thể thêm 1 feature mới bằng cách lũy thừa x lên:

hoặc lấy căn của nó:

Một điều quan trọng là khi bạn biến đổi các feature như thế này, vùng giá trị của nó sẽ trở nên cách biệt so với feature gốc. Lúc này, bạn sẽ phải áp dụng những cách tối ưu như
Feature ScalingvàMean Normalizationđã nói ở trên để tối ưu thuật toán Gradient Descent.
