

Bài 2 phần 2 trong khóa học Machine Learning của giáo sư Andrew Ng. Trong bài này, ta sẽ tìm hiểu một cách thay thế cho thuật toán Gradient Descent cùng ưu nhược điểm của nó.
Xem các bài viết khác tại Machine Learning Course Structure
1. Normal Equation
Thuần túy về mặt toán học, đối với 1 hàm hypothesis, ta có thể tìm ra giá trị nhỏ nhất của nó bằng cách lấy đạo hàm, và tìm x khi đạo hàm = 0.
1.1. Công thức
Áp dụng cách nhân matrix với vector đã được giới thiệu ở bài trước, ta có công thức như sau:
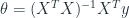
1.2. So sánh
| Gradient Descent | Normal Equation |
|---|---|
| Cần phải chọn alpha | Không cần chọn alpha |
| Cần nhiều vòng lặp | Tính bụp phát ra luôn |
Độ phức tạp  |
Độ phức tạp  , cần phải tích nghịch đảo của , cần phải tích nghịch đảo của  |
| n lớn vẫn chạy tốt | Chậm nếu n quá lớn |
Tóm lại, nếu số lượng các feature quá lớn thì bạn nên sử dụng thuật toán Gradient Descent để nhanh ra kết quả.
1.3. Non-invertibility (không thể đảo ngược)
Trong một số trường hợp hiếm gặp, kết quả của noninvertible.
Điều này xảy ra là do các nguyên do sau:
+ Có các feature bị dư. Ví dụ như 2 feature có liên quan rất chặt chẽ với nhau (feature này phụ thuộc vào feature kia một cách tuyến tính chả hạn)
+ Có quá nhiều features (m <= n).
Để giải quyết vấn đề này, ta có thể delete bớt các feature bị dư (kiểu như x1 là diện tích theo mét vuông, x2 là diện thích theo dặm), hoặc dùng các phương pháp regularization sẽ được nói đến ở các phần sau.
